Non ci sono prodotti a carrello.
Facciamo una panoramica sulle Reti Neurali, sui modelli che le sostengono e valutiamone l’implementazione attraverso la piattaforma Arduino.
Dopo aver introdotto il concetto di Intelligenza Artificiale nell’articolo sui sensori pubblicato nel fascicolo precedente, vediamo come applicare le tecniche di AI all’hardware Arduino, Raspberry Pi ed anche ai tradizionali microcontrollori.
La necessità di queste tecniche nasce dalla considerazione che la programmazione classica diventa impraticabile quando si ha a che fare con molti input sensoriali di tipo analogico (ovvero che forniscono valori continui) e con attuatori non di tipo ON/OFF come motori e servocomandi; in questi casi è conveniente orientarsi verso Reti Neurali.
In queste pagine cerchiamo di chiarire cosa sono e come possono essere utilizzate in un hardware minimale come Arduino. Le utilizzeremo a cominciare da un semplice sistema di “obstacle avoidance” ossia di movimento evitando ostacoli e rimanendo in perimetri definiti. Per questo esempio utilizzeremo la piattaforma robotica “Ardusumo” ma nulla vieta di impiegare altri robot semoventi come “Alphabot”.
Reti Neurali
Le Reti Neurali traggono origine dalla definizione del Percettrone, che Frank Rosenblatt creò nel 1958 ispirandosi al funzionamento dei neuroni.
La loro applicabilità risale però all’introduzione delle funzioni di trasferimento non lineari e dell’algoritmo di correzione degli errori “Error Back Propagation” (Rumelhart and McClelland, 1986) riconducibili agli anni “ottanta” del secolo scorso.
Delle Artificial Neural Network (ANN) o più brevemente NN, è poi nata una branca chiamata “connessionismo”. Il nome è abbastanza autoesplicativo, in quanto la tecnica delle NN prevede una computazione distribuita su diversi nodi interconnessi.
Una Rete Neurale è composta, in genere, da almeno tre strati di nodi connessi in catena: il primo è sostanzialmente un semplice buffer di input, mentre il terzo realizza un buffer di output. In realtà, poiché lo strato di input non ha una funzione che non sia quella di propagare l’input verso il primo vero strato elaboratore, molto spesso le reti di questo tipo vengono chiamate reti a due soli strati. Venendo al nostro esempio con “Ardusumo”, il primo strato raccoglie gli input sensoriali e l’ultimo l’azionamento dei motori (Fig. 1). In mezzo c’è un importantissimo strato, in genere chiamato strato nascosto (hidden) perché non è in rapporto diretto con l’esterno.
Naturalmente esistono versioni di NN molto più complesse (Fig. 2), con più strati intermedi, con collegamenti inter-strato (convolution NN) o con buffer di memoria temporanea per la simulazione di sistemi dinamici, in cui lo stato precedente ha la sua importanza (recurrent NN); per il momento ci riferiremo alla versione base delle NN, che può già rappresentare un ottimo approssimatore universale di funzioni (in->out).
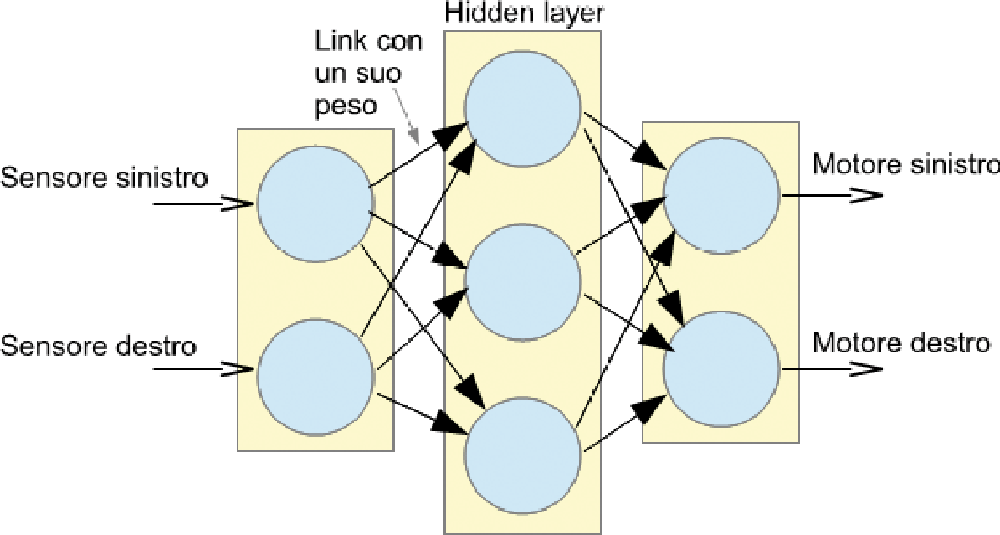
Fig. 1 Semplice rete neurale utilizzata per pilotare Ardusumo.
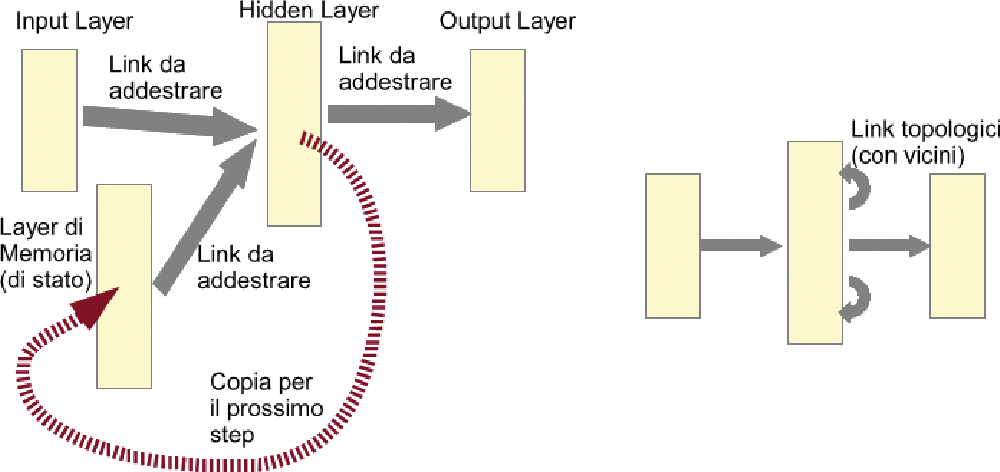
Fig. 2 Alcune tipologie di NN.
L’elemento fondamentale della rete neurale è il nodo. Questo raccoglie l’output dei nodi dello strato precedente ognuno moltiplicato per il peso del link corrispondente.
Nella struttura classica tutti questi valori vengono sommati a formare un valore, chiamato attivazione del nodo, che viene passato ad una funzione di trasferimento che fornisce l’output effettivo del nodo.
Questo output sarà propagato ai nodi dello strato successivo. Lo scopo della funzione di trasferimento (chiamata anche funzione di attivazione) è cruciale. Infatti proprio l’adozione di funzioni non lineari ha permesso alle reti neurali di diventare degli approssimatori universali, in quanto, insieme al metodo intelligente di correzione degli errori, permettono di trasformare lo spazio dei valori di input in uno spazio fittizio che può risolvere qualunque associazione input->output, a patto di avere un numero adeguato di nodi intermedi.
Per permettere questa proiezione da uno spazio vettoriale ad un altro, la funzione di attivazione è in genere di tipo “squashing”, cioè comprime l’output entro valori massimi e minimi, in modo da costringere i pesi delle connessioni ad evolvere in modo complesso.
Le funzioni di attivazione che sono state proposte sono molte, ma le più utilizzate sono quella sigmoide (detta anche logistica) (1/(1+exp(-x)), la tangente iperbolica e quella rettificatrice (ReLU), insieme ovviamente a quella lineare unitaria utile in certe situazioni (Fig. 3).
Le reti neurali sono un sistema Feed Forward (in avanti dall’input all’output) ad apprendimento supervisionato, ovvero vengono inizialmente costruite con pesi casuali nelle connessioni e poi addestrate tramite un numero consistente di coppie di valori input->output. In questo modo finiscono per approssimare, interpolare ed estrapolare una funzione che lega un input multidimensionale ad un output multidimensionale anche in modo complesso; in sostanza, compiono una sorta di regressione statistica multivariata.
Il meccanismo è noto con il nome di Error Back Propagation (EBP); in pratica, a partire dall’output prodotto spontaneamente dalla rete in seguito a certi valori di input, si determina l’errore quadratico commesso da ogni nodo di output e si determina la sua derivata in funzione dei singoli pesi afferenti al nodo. A questo punto si correggono i pesi applicando ad essi una variazione proporzionale all’opposto della derivata così calcolata.
L’efficacia del metodo sta nel fatto che l’errore quadratico si può riportare indietro allo strato precedente applicando la regola della catena delle derivate; in questo modo si aggiornano i pesi di tutte le connessioni ottimizzando l’errore quadratico medio della rete complessiva.
Non è garantito il raggiungimento dell’ottimo assoluto, ma sicuramente l’errore scende fino a quando può fermarsi a un valore minimo. Se il numero dei nodi di input è stabilito dal numero delle grandezze di ingresso e quello dei nodi di output è definito dalle grandezze di uscita, i nodi dello strato intermedio sono da decidere, in fase progettuale, un po’ per esperienza, un po’ in funzione della complessità della funzione da approssimare ed un po’ per tentativi.
Troppo pochi possono non far scendere l’errore in modo soddisfacente, mentre troppi possono portare la rete a non sintetizzare in modo efficiente il legame input->output che si vuole approssimare. Una volta addestrata la rete può essere utilizzata, per eseguire la funzionalità che ha imparato, fornendo un input e rilevando l’output.
C’è da notare che non si tratta di ripetere gli esempi, ma di poter contare sulla generalizzazione di una funzione multidimensionale anche complessa, appresa a partire da un numero limitato di esempi prototipali.
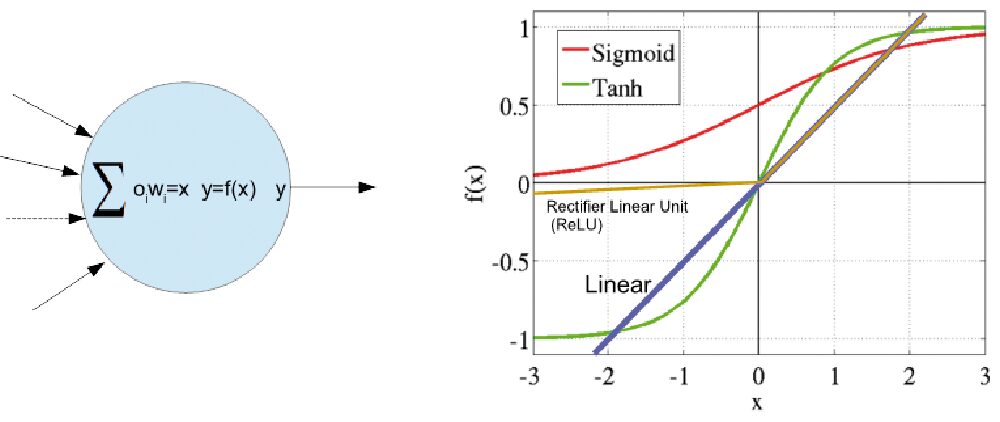
Fig. 3 Nodo e funzioni di attivazione comuni.

Tabella 1 Funzioni della libreria NNet.
Libreria NNet per Arduino
Benché esista in Internet qualche esempio di libreria di reti neurali per Arduino, si è preferito svilupparne una per cercare di renderla molto leggera e di facile utilizzo. La libreria occupa meno di una decina di kilobyte ed è abbastanza veloce.
La libreria inoltre può funzionare su Arduino ma anche su un PC; infatti esiste un “define” che, disabilitato, permette alcune funzionalità in genere non disponibili su Arduino, come il salvataggio della rete o l’output su file.
La libreria permette di definire reti a tre strati con numero di nodi a piacere. Il primo strato (Layer 0) ha il compito di ricevere i valori di input ed è in realtà fittizio perché ha il solo scopo di propagare questi valori allo strato successivo tramite le sue connessioni ad esso. Il secondo strato (Layer 1), può avere una funzione di attivazione scelta fa quelle disponibili (NodeLin, NodeSigm, NodeTanh, NodeReLU).
Infine il terzo strato (Layer 2) è quello da cui si preleva l’output e può avere anch’esso una funzione di attivazione scelta fra quelle disponibili. I nodi vengono tutti collegati automaticamente con quelli dello strato successivo con pesi casuali molto piccoli.
La libreria permette anche di caricare una rete già addestrata e quindi con i valori dei pesi ben definiti. Una funzione di “Learn” permette di addestrare la rete ed una funzione di “Forward” permette di utilizzarla quando è addestrata.
Infine sono presenti funzioni di stampa per salvare/evidenziare la struttura della rete. Nella Tabella 1 vedete le funzioni della libreria.
Esempio con la funzione XOR
Un modo classico per evidenziare il funzionamento delle reti neurali Feed Forward è quello di addestrarli a simulare la funzione XOR (Fig. 4).
La scelta di questa funzione, che è comunque non analogica, si basa sul fatto che è una funzione non lineare degli input.
Ovvero, non c’è modo di separare i risultati 0 ed 1 dai valori di input con un semipiano.
Nella libreria è compreso questo esempio che può essere lanciato su Arduino.
Dopo un paio di migliaia di presentazioni di esempi (qualche secondo su Arduino), la rete risponde correttamente. Dalla Fig. 5 si vede in che modo una rete neurale può essere pensata come un sistema che proietta spazi su spazi, anche deformandoli.
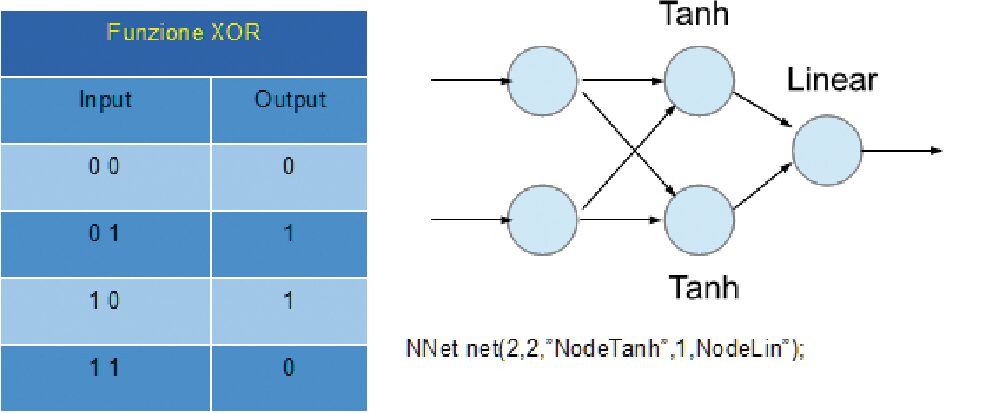
Fig. 4 Rete Neurale per funzione XOR.
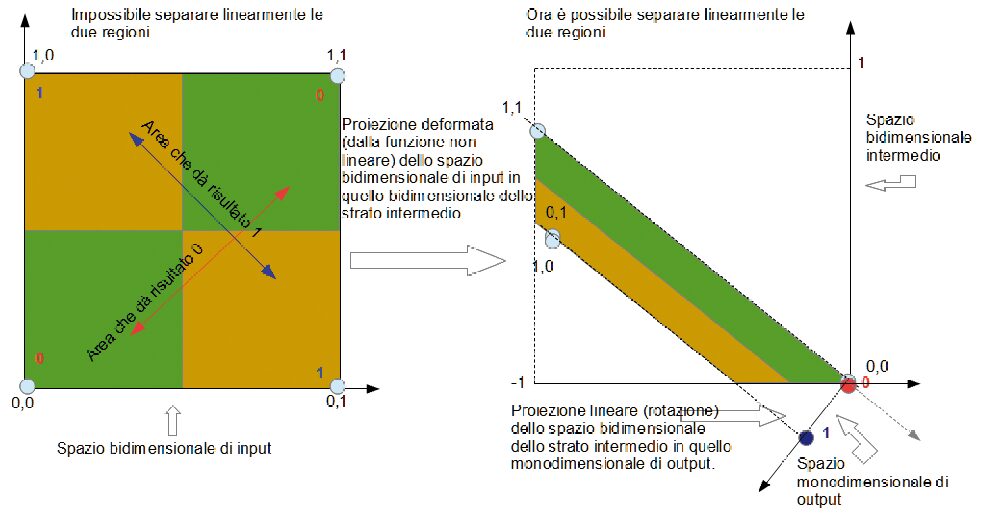
Fig. 5 Interpretazione geometrica del funzionamento della rete oer lo XOR.
Rete Neurale per pilotare Ardusumo
Ardusumo (Fig. 6) è un rover che può contare fra l’altro su due sensori di distanza a infrarossi con una portata da 40 cm a 5 cm circa e su due motori che comandano due ruote, la cui potenza viene regolata con il sistema PWM attraverso il classico circuito a ponte TB6612FNG.
I due sensori IR (orientati a circa ±30° rispetto alla direzione di marcia) forniscono un segnale inversamente proporzionale alla distanza come descritto dalla Fig. 7.

Fig. 6 Il robot Ardusumo.

Fig. 7 Risposta del sensore ad infrarosso Sharp 2D120X.
Abbiamo quindi due sensori analogici e due motori pilotabili con continuità per andare indietro, curvare o procedere in avanti. Come potremmo fare a pilotare il rover con l’esigenza di fargli evitare gli ostacoli? Una prima possibilità è quella di utilizzare delle soglie di distanza e dei livelli di potenza discreti. Poi in base a questi valori digitali costruire una strategia basata sostanzialmente in una “look table” o una serie di “if”.
Un’alternativa più elegante è utilizzare direttamente i livelli analogici per esempio mediante una struttura in logica “Fuzzy”, oppure, come in questo esempio, con una rete neurale. La struttura utilizzata è una rete con 2 nodi di input, 3 nodi hidden e 2 nodi di output.
La funzione di attivazione dello strato hidden è la tangente iperbolica, cosi come per lo strato di output (più che altro per mantenere l’escursione della potenza dei motori tra -1 e +1). L’input riceve direttamente i valori di tensione normalizzati (0 -:- 1); mentre l’output viene scalato moltiplicandolo per 255 (massimo valore PWM). Quindi l’istanza della rete sarà:
NNet net(2,3,”NodeTanh”,2,”NodeTanh”);
Ora sorge il problema di come addestrarla e allo scopo ci sarebbero due modi:
1. per imitazione, vale a dire pilotandola con un comando remoto mentre apprende;
2. fornendo una serie di esempi prototipali studiati per coprire le situazioni principali.
Proveremo ad utilizzare il secondo, riferendoci alla Tabella 2, dove sono elencati i 16 esempi di addestramento. Essi non devono essere in ordine, anzi è sempre opportuno sottoporre gli esempi scegliendoli a caso dalla lista.
Dopo alcune decine di migliaia di cicli di addestramento (pochi secondi su Arduino, e quasi istantaneamente su PC), si ottiene un errore quadratico medio abbastanza basso.
A questo punto potrebbe sorgere la domanda: quando la rete può considerarsi addestrata? Questo è un punto delicato per le reti neurali.
Se c’è una misura dell’errore che può discriminare in maniera effettiva, allora basta mettere una soglia e fermarsi al raggiungimento di quest’ultima.
Ma in molti casi questo non è possibile, allora si può ricorrere allo stratagemma di preparare un secondo set di esempi differenti; presentarli alla rete per l’elaborazione e vedere se i risultati corrispondono a quelli aspettati. In alternativa è possibile verificare direttamente la funzione appresa se, come in questo (raro) caso, è possibile graficarla in virtù della ridotta dimensionalità.
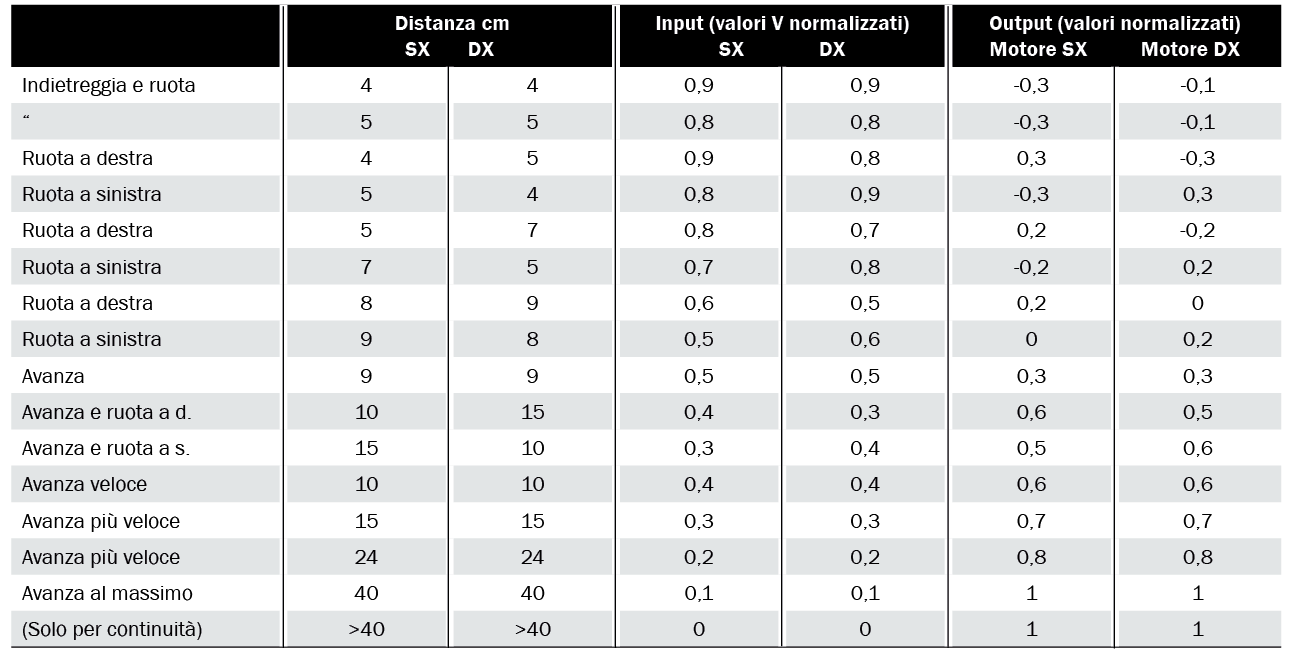
Tabella 2 Esempi di training per Ardusumo.
Per realizzare i grafici si è alimentata la rete addestrata con valori consecutivi per l’input sinistro e destro e si sono raccolti i valori di output (per praticità è stato utilizzato un PC).
In Fig. 8 sono visualizzate le superfici corrispondenti ai valori per i motori sinistro e destro in funzione dei valori caricati sugli input.
In Fig. 9 sono invece mostrate le stesse superfici ma in funzione delle distanze (che sono inversamente proporzionali ai valori di tensione).
La semplice rete di Fig. 10 ha prodotto funzioni continue complesse difficilmente realizzabili con altri sistemi; anche questo esempio è incluso nella libreria, sotto forma di rete addestrata. Ma ovviamente è possibile addestrare la rete con diversi o più numerosi esempi ottenendo comportamenti che possono essere anche più efficienti.
La libreria NNet è scaricabile dal sito https://github.com/open-electronics/Artificial_Intelligence. Dal sito è possibile anche scaricare un breve filmato di Ardusumo pilotato dalla rete neurale, così da evidenziare il tipo di funzionalità messa in atto concretamente dalla rete.
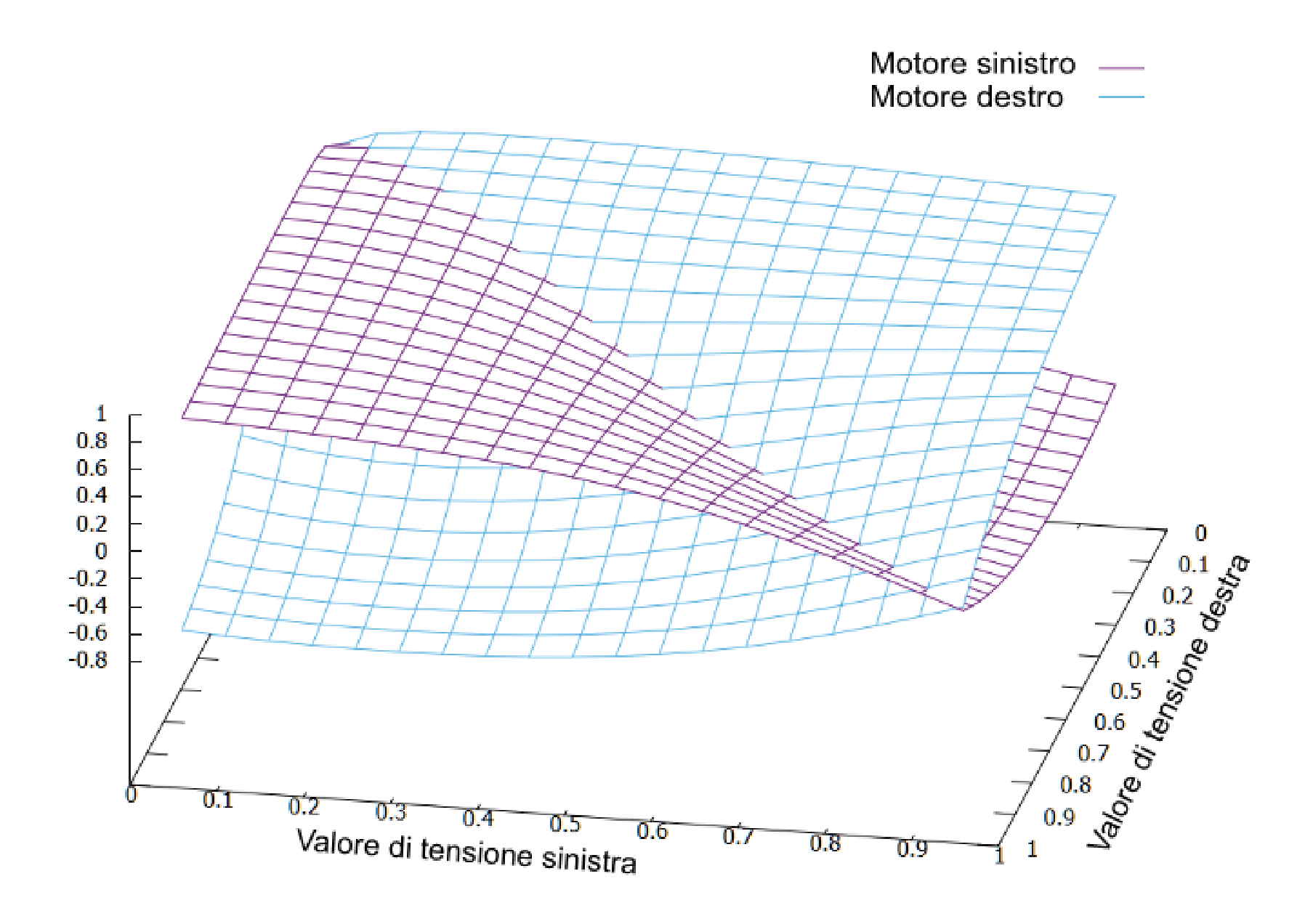
Fig. 8 Valori del motore sinistro e destro in funzione della tensione.

Fig. 9 Valore del motore sinistro e destro in funzione delle distanze.

Fig. 10 Rete addestrata che pilota Ardusumo.
Dimensioni di reti possibili su Arduino Uno
Vediamo ora quali dimensioni di reti possiamo caricare su un Arduino Uno.
La libreria Neural Network occupa meno di 8Kbyte, quindi solo circa il 22% della memoria di programma di Arduino Uno.
Il problema è la memoria di lavoro, sulla quale va definita la rete e le altre variabili del programma, che è molto scarsa. In pratica non possiamo allocare più di circa 300 parametri (nodi + link).
In termini concreti possiamo creare al massimo una rete di 6 input, 24 nodi hidden e 8 nodi di output; oppure 10 nodi di input, 14 nodi hidden e 10 nodi di output; oppure 2 nodi di input, 50 nodi hidden e 2 nodi di output; o qualunque altra combinazione intermedia.
Va comunque tenuto presente che con queste dimensioni massime rimane pochissimo spazio per altre eventuali variabili di programma.
Conclusioni
In questo articolo vi abbiamo spiegato come sia possibile utilizzare la tecnologia delle reti neurali anche con Arduino. Al prezzo di un certo lavoro nel definire la rete e gli esempi da sottoporre per l’addestramento e, soprattutto, a fronte di qualche difficoltà nel definire il completamento dell’addestramento, si possono utilizzare semplici e rapidissime strutture che, una volta addestrate, ricreano complesse funzioni multidimensionali continue.


